
fingertips
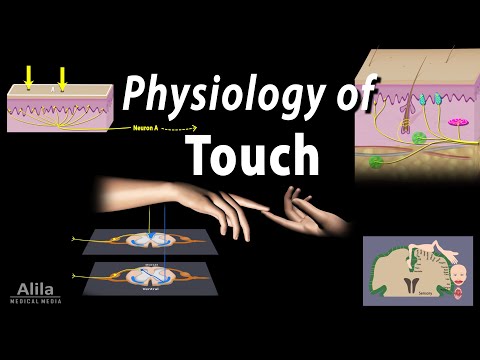
Q. What is the relationship between the two point threshold and the receptive field?
The model predicts that the two-point threshold is higher in the long axis of receptive fields In the human it is higher in the long axis of the arm, which might mean that the receptive fields are elongated in this axis too
Q. What does the receptive field of a visual neuron mean?
The receptive field is often identified as the region of the retina where the action of light alters the firing of the neuron
Q. How do you calculate effective receptive fields?
6 Answers
- It is the size of the area of pixels that impact the output of the last convolution
- For each convolution and pooling operation, compute the size of the output Now find the input size that results in an output size of 1×1
- You don’t need to use a library to do it
Q. What is the shape of a receptive field of a ganglion cell?
elliptical
Q. What are visual receptive functions?
Definition The term receptive field refers to the region of visual space where changes in luminance influence the activity of a single neuron Also known as the classical receptive field (CRF) Receptive fields of different types of cells in the visual pathway have different substructures
Q. Which ganglion cells have the largest receptive field?
Non-M, non-P ganglion cells, which have not yet been well characterized, account for the remaining 5% In addition to being larger themselves, type M ganglion cells have larger receptive fields, propagate action potentials more quickly in the optic nerve, and are more sensitive to low-contrast stimuli
Q. Where are the receptive fields for V1 neurons?
In many neurons this arrangement is accompanied by selectivity for binocular depth, or disparity (Cumming and DeAngelis, 2001) Each V1 neuron has two receptive fields, one per each ey
Q. Which receptive field property is first found in V1?
V1 is “primary” because the LGN sends most of its axons there, so V1 is the “first” visual processing area in the cortex V1 processes the information coming from the LGN (as described below) and then passes its output to the other visual cortical areas which are (creatively) named V2, V3, V4, etc
Q. What is Retinotopic mapping?
Retinotopy (from Greek τόπος, place) is the mapping of visual input from the retina to neurons, particularly those neurons within the visual stream Even more complex maps exist in the third and fourth visual areas V3 and V4, and in the dorsomedial area (V6)
Q. What is receptive field size?
“the receptive field size for the layer This is the size (in pixels) of the local image region that affects a particular element in a feature map” which makes sense with the traditional definition of a receptive field Its usually thought as the number of pixels that affect a particular node in the feature ma
Q. How do you increase receptive fields?
The receptive field size of a unit can be increased in a number of ways One option is to stack more layers to make the network deeper, which increases the receptive field size linearly by theory, as each extra layer increases the receptive field size by the kernel size
Q. What is effective receptive field?
As a natural consequence, one can define the relative importance of each input pixel as the effective receptive field (ERF) of the feature In other words, ERF defines the effective receptive field of a central output unit as the region that contains any input pixel with a non-negligible impact on that uni
Q. What is a local receptive field?
The local receptive field is a defined segmented area that is occupied by the content of input data that a neuron within a convolutional layer is exposed to during the process of convolution The LeNet paper introduced the first use case of the utilization of the convolutional neural network for character recognitio
Q. What is receptive field machine learning?
The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (ie be affected by) A receptive field of a feature can be described by its center location and its siz
Q. What is pool size in CNN?
The pooling layer operates upon each feature map separately to create a new set of the same number of pooled feature maps The size of the pooling operation or filter is smaller than the size of the feature map; specifically, it is almost always 2×2 pixels applied with a stride of 2 pixel
Q. What is stride in CNN?
Stride is the number of pixels shifts over the input matrix When the stride is 1 then we move the filters to 1 pixel at a time When the stride is 2 then we move the filters to 2 pixels at a time and so on The below figure shows convolution would work with a stride of 2
Q. Why do we use ReLU in CNN?
The Rectified Linear Unit, or ReLU, is not a separate component of the convolutional neural networks’ process It’s a supplementary step to the convolution operation that we covered in the previous tutorial The purpose of applying the rectifier function is to increase the non-linearity in our image
Q. Why does CNN work?
According to a MathWork post, a CNN convolves learned features with input data, and uses 2D convolutional layers, making this architecture well suited to processing 2D data, such as images Since CNNs eliminate the need for manual feature extraction, one doesn’t need to select features required to classify the image
Q. Why do we use stride in CNN?
Stride controls how the filter convolves around the input volume In the example we had in part 1, the filter convolves around the input volume by shifting one unit at a time The amount by which the filter shifts is the stride Stride is normally set in a way so that the output volume is an integer and not a fractio
Q. What is a filter in CNN?
In Convolutional Neural Networks, Filters detect spatial patterns such as edges in an image by detecting the changes in intensity values of the imag
Q. How is CNN different from Ann?
The major difference between a traditional Artificial Neural Network (ANN) and CNN is that only the last layer of a CNN is fully connected whereas in ANN, each neuron is connected to every other neurons as shown in Fig 2
Q. What is the purpose of Max pooling?
Max pooling is a sample-based discretization process The objective is to down-sample an input representation (image, hidden-layer output matrix, etc), reducing its dimensionality and allowing for assumptions to be made about features contained in the sub-regions binne
Q. Is Max pooling necessary?
Pooling is neither necessary nor sufficient for appropriate deformation stability in CNN
Q. Why do we do pooling?
Why to use Pooling Layers? Pooling layers are used to reduce the dimensions of the feature maps Thus, it reduces the number of parameters to learn and the amount of computation performed in the network The pooling layer summarises the features present in a region of the feature map generated by a convolution laye
Q. Which answer explains better the flattening?
Which answer explains better the ReLU? Helps in the detection of features, decreasing the non-linearity of the image, converting negative pixels to zero This behavior allows you to detect variations of attributes It is used to find the best features considering their correlation




